AWS Architecture Design: A Start-up case study
I came across an interesting scenario about a start-up looking to migrate their existing application onto cloud (AWS in this case). This blog post outlines my take on the solution. Feedback is welcome!
Scenario
Imagine you meet a small startup company planning to launch a new application that allows consumers & service providers to interact in real time. Currently, their architecture uses LAMP stack comprising of open-source software. Like many small start-ups they are confident that they will be the next big thing and expect significant, rapid, yet un-quantified growth in the next few months. With this in mind, they are concerned about the following:
- Scaling to meet the demand, but with uncertainty around when and how much this demand will be – they are very concerned about buying too much infrastructure too soon or not enough too late!
- Disaster Recovery planning, since this application is core their business.
- Manage user identities & sync user specific data across multiple devices.
- Ability for Service Providers to send notifications to consumer.
- Ability to run analytics on top of collected data, with analytics they should be able to visualize & understand app data usage.
- Ability to configure their database and data access layer for high performance and throughput.
- Effective distribution of load.
- A self-healing infrastructure that recovers from failed service instances.
- Security of data at rest and in transit.
- Securing access to the environment as the delivery team expands.
- An archival strategy for inactive objects greater than 6 months.
- Ability to easily manage and replicate multiple environments based on their blueprint architecture.
Objective
Recommend a manageable, secure, scalable, high performance, efficient, elastic, highly available, fault tolerant and recoverable architecture that allows the startup to organically grow. The architecture should specifically address the requirements/concerns as described above.
Assumptions
- The application is already built, and no significant changes need to be made to host it in AWS.
- The application is considered to be business critical for the start-up.
- The application is built using typical three-tier architecture.
- The delivery team would be connecting with the AWS environment over the internet. If private connectivity is required then additional services like VPN, AWS DirectConnect would required to be setup.
- Access to AWS account(s) will be controlled through AWS Identity and Access management (IAM), integration with external identity provider and SSO is not considered.
- There are no specific compliance requirements defined for this workload like HIPAA, PCI-DSS, FedRAMP etc.
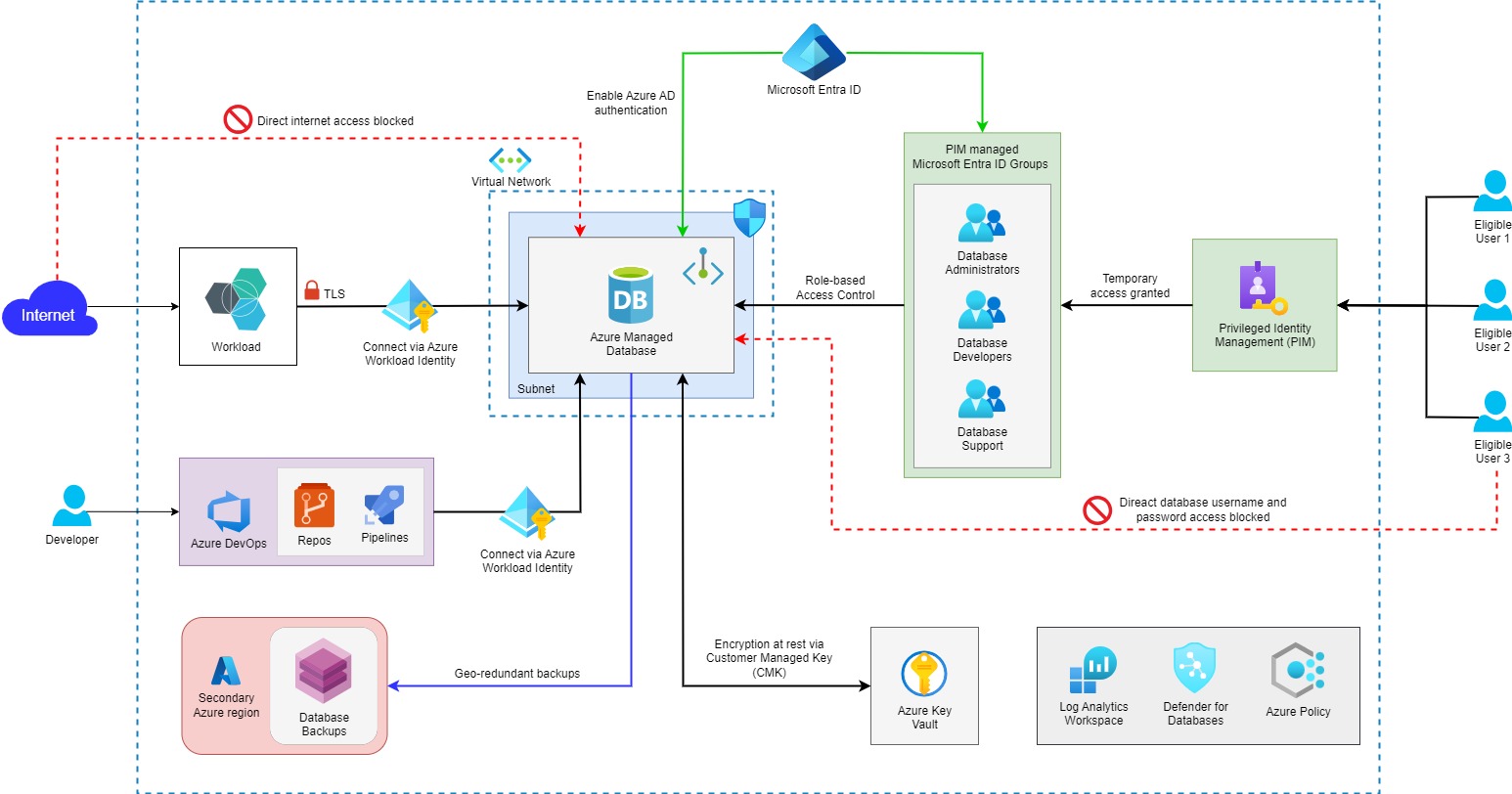
Solution

Download a draw.io file of this architecture.
Solution Flow
- Customer/Service Provider (User) initiates real-time interaction through the client app. User is redirected to Amazon Cognito for sign-in/sign-up.
- After successful authentication the client app receives the access token from Amazon Cognito.
- Amazon Cognito also enables the sync of user specific data across multiple devices.
- The client app communicates with the backend APIs through Amazon Route 53. Route 53 decides which region the request should be forward to based on the routing rules.
- The request is forwarded to Application Load Balancer from Route 53 where it is inspected by Web Application Firewall for vulnerabilities.
- If no vulnerabilities are detected Application Load Balancer sends the request to Elastic Beanstalk auto-scaling group where the request is processed by one of the application instances.
- Application interacts with the Amazon Aurora database through RDS proxy and performs the request CRUD operations on the database and returns the response back to the application.
- Amazon Pinpoint continuously collects usage data from application and makes it available for analysis. The data is also continuously exported to Amazon S3 since Amazon Pinpoint can only store data for 90 days. Additionally, Amazon QuickSight is used to perform advanced analytics and create interactive dashboards.
- Any data older than 6 months is archived to Glacier by using S3 lifecycle management policy.
- Based on the analysis provided by Amazon Pinpoint the application can trigger push notifications to specific (or all) users.
- The developer checks-in the code changes to AWS CodeCommit, the code is scanned for credentials leak, code quality, open-source vulnerabilities etc.
- AWS CodeBuild then builds the required container image(s) and pushes the image(s) to AWS Elastic Container Registry (ECR).
- In ECR the container images are scanned for any vulnerabilities using Amazon Inspector.
- AWS CodeDeploy then pushes the new version to Elastic Beanstalk. Elastic Beanstalk pulls the latest image from ECR and initiates the deployment process.
- The delivery team accesses the AWS account using IAM credentials to perform their tasks, principle of least privileges is followed when granting access to the delivery team members.
- All services are monitored using AWS CloudWatch and AWS CloudTrail.
- AWS Cost management tools are used for creating budgets and cost alerts.
- AWS Trusted Advisor recommendations are reviewed periodically to ensure that the application remains in a Well-Architected state.
Meeting Start-up requirements
1. Scaling to meet the demand, but with uncertainty around when and how much this demand will be – they are very concerned about buying too much infrastructure too soon or not enough too late!
Keeping in mind the uncertainty around application demand, the AWS services proposed in this architecture leverage built-in auto-scaling strategy to allow the start-up to consume services on-demand – as little as they need or as much as they need. As the demand varies the architecture can scale in and out.
- Amazon Elastic Beanstalk - Elastic Beanstalk has been provisioned in High Availability configuration in which it uses EC2 auto-scaling group to ensure that the number of instances increase and decrease based on demand. This configuration automatically provisions an Elastic load balancer to distribute traffic amongst the auto-scaling group. Since there is uncertainty in demand, Elastic Beanstalk allows the start-up to start small and without the need to over-provision. The capacity can auto-scale based on the demand.
- Amazon Aurora Serverless for MySQL – The serverless offering provides on-demand, auto-scaling configuration for Amazon Aurora. The startup can simply create a database, specify the desired database capacity range and connect their application. Aurora will automatically adjust the capacity within the range they specified based on the application’s needs. The best part is they will only pay for the database capacity, storage, and I/O the database consumes when it is active. The database capacity automatically scales up or down to meet their workload needs and shuts down during periods of inactivity, saving them money as well as administration time.
- Amazon RDS Proxy – Using RDS Proxy, the application can handle unpredictable surges in database traffic that otherwise might cause issues due to oversubscribing connections or creating new connections at a fast rate. RDS Proxy establishes a database connection pool and reuses connections in this pool without the memory and CPU overhead of opening a new database connection each time.
- Other services like S3, Amazon Pinpoint, Elastic container registry, Glacier, Application Load Balancer etc. all auto-scale based on demand. The start-up only pays for the capacity that they are consuming with no required commitments.
2. Disaster Recovery planning
Based on the start-up requirements and their dependency on this application, a Warm standby disaster recovery strategy is suggested in this case to minimize the recovery time:
- Pre-provision the networking infrastructure like VPC, Subnets, Internet Gateway, NAT Gateway etc. in the secondary region.
- Starting with the application tier, a warm standby of the Elastic Beanstalk environment is provisioned in the secondary region. To optimize the cost the environment is kept is kept at minimal scale. Route 53 failover strategy will be leveraged to route the traffic to standby region in case of a failure in the primary region.
- Since data is the most crucial part of the business, ensuring its protection and resiliency is of highest priority. For this purpose, Amazon Aurora database is configured to maintain a read replica in the secondary region. In an event of disaster this read replica will be promoted to primary status.
- Any data in S3 bucket is also replicated to secondary region by using the cross-region replication feature.
- Built-in cross-region replication features are configured for AWS Services like Elastic Container Registry, AWS KMS, Secret Manager.
- On every release the DevOps process is utilized to deploy the new version of the application in both Primary and Secondary regions. This keeps the secondary region up to date with any application changes. However, the AWS DevOps services are region scoped and do not provide built-in disaster recovery or geo-replication features, in case of disaster the startup could lose the ability to do code check-ins and perform on-demand application deployment. AWS recommends creating two repositories in different regions and configuring Git client to push changes to both respositores at once.
- Amazon Cognito is one of the most critical services in this architecture and servers as the entry point for users. Unfortunately, it is a region scoped service and does not support built-in disaster recovery to the secondary region. AWS provides guidance on developing custom solution for replicating user pools across regions. Since this is the most crucial service it is advisable to put development effort into building a custom replication solution. Here is an example of one way of achieving this How UnitedHealth Group Improved Disaster Recovery for Machine-to-Machine Authentication. However, in case the development effort is very high, advice is to explore similar 3rd party solutions like Azure AD B2C, Okta etc. which offer built-in DR.
3. Manage user identities & sync user specific data across multiple devices
Amazon Cognito is used for handling user authentication and authorization for the application. Amazon Cognito Sync is a feature of Cognito that enables cross-device syncing of application-related user data. This feature can be used to synchronize user profile data across mobile devices and web applications.
4. Ability to run analytics on top of collected data, with analytics they should be able to visualize & understand app data usage
- Amazon Pinpoint is an AWS service that start-up can use to engage with their customers across multiple channels. Using Amazon Pinpoint start-up can analyse and understand their application usage as well as customer behaviour. They can get insights like how many customers use their application, which features does the customer use most, retention rate etc. They can use this data to improve the usability of their application and to increase customer engagement, satisfaction, and retention. Amazon Pinpoint also offers visualization features.
- Amazon Pinpoint can save the collected data for up to 90 days. To keep the data for long term analytics and compliance requirements, the data is moved to S3 bucket. Additionally, the start-up can use Amazon QuickSight to perform advanced analytics and create interactive dashboards.
5. Ability for Service Providers to send notifications to consumer
Amazon Pinpoint is used for sending push notifications to the customers.
6. Ability to configure their database and data access layer for high performance and throughput
Amazon Aurora Serverless for MySQL database is recommended for the start-up in this scenario. Amazon Aurora delivers 5x performance and throughput over stock MySQL. The serverless offering provides on-demand, auto-scaling configuration for Amazon Aurora. This will allow the start-up to run their database in AWS without managing database capacity. Manually managing database capacity can take up valuable time and can lead to inefficient use of database resources. With Aurora Serverless, they can simply create a database, specify the desired database capacity range, and connect their application. Aurora will automatically adjust the capacity within the range they specified based on the application’s needs. The best part is they will only pay for the database capacity, storage, and I/O the database consumes when it is active. The database capacity automatically scales up or down to meet their workload needs and shuts down during periods of inactivity, saving them money as well as administration time.
7. Effective distribution of load
The architecture proposes multi-level traffic distribution:
- Level 1: To handle cross-region traffic routing and failover, the architecture makes use of Route 53.
- Level 2: To enable load balancing at the instance level, the Elastic Beanstalk environment is equipped with an Application Load Balancer to distribute traffic among the multiple EC2 instances hosting the application workload.
8. A self-healing infrastructure that recovers from failed service instances
All the services proposed for this architecture leverage the AWS Availability Zones to ensure high availability and resilience:
- Route 53 is a global service and offers 100% availability SLA. Application Load Balancer is inherently HA with built-in support for leveraging multiple AZs.
- Both Elastic Beanstalk and Amazon Aurora ensure high availability by leveraging the multi-AZ deployment.
- Other services like Amazon S3, Amazon Cognito, KMS, Amazon Pinpoint, Kinesis Data Firehose, AWS DevOps services etc. are region scoped and inherently highly available. These services are built to leverage multiple availability zones and any infrastructure issues are automatically mitigated to ensure resiliency.
9. Security of data at rest and in transit
The proposed architecture relies on multiple services for storing and accessing the data:
- Amazon Aurora Serverless for MySQL – Data at rest is encrypted using Keys from AWS Key Management Service. The encryption is applied to not only the data at rest but also to the automated backups, snapshots, and replicas of the database. Amazon Aurora uses SSL/TLS to secure data in transit.
- Amazon S3 – Data at rest is encrypted using Keys from AWS Key Management Service. Data in transit is protected using SSL/TLS.
- Glacier – Data at rest stored in S3 Glacier is automatically server-side encrypted using 256-bit Advanced Encryption Standard (AES-256) with keys maintained by AWS. Data in transit is protected using SSL/TLS.
- Elastic Container Registry (ECR) – Amazon ECR stores images in Amazon S3 buckets that Amazon ECR manages. By default, Amazon ECR uses server-side encryption with Amazon S3-managed encryption keys which encrypts your data at rest using an AES-256 encryption algorithm. Data in transit is protected using SSL/TLS.
- Amazon Pinpoint – Any data stored in Amazon Pinpoint is encrypted at rest automatically using internal AWS Key Management Service keys that the service owns and maintains on behalf of the users. To protect data in transit, Amazon Pinpoint uses HTTPS and Transport Layer Security (TLS) 1.0 or later to communicate with clients applications. To communicate with other AWS services, Amazon Pinpoint uses HTTPS and TLS 1.2.
- AWS Cognito – Data encryption at rest is automatically handled by Amazon Cognito in accordance with industry standards. To protect data in transit, all requests to Amazon Cognito must be made over the Transport Layer Security protocol (TLS). Clients must support Transport Layer Security (TLS) 1.0 or later.
- AWS Identity and Access Management (IAM) - Data collected and stored within IAM includes IP addresses, customer account metadata, and customer identifying data that includes passwords. Customer account metadata and customer identifying data are encrypted at rest using AES 256 or is hashed using SHA 256. Customer identifying data, including passwords, is encrypted in transit using TLS 1.1 and 1.2.
- Data to and from application – AWS Certificate Manager is used to store and access SSL certificates used by various services to protect the data to and from the application.
- AWS CodeCommit – CodeCommit repositories are automatically encrypted at rest. No customer action is required. CodeCommit also encrypts repository data in transit. You can use either the HTTPS protocol, the SSH protocol, or both with CodeCommit repositories.
10. Securing access to the environment as the delivery team expands
Delivery team or any other stakeholders are given access to AWS environment through AWS Identity and Access Management (IAM). IAM user groups have been leveraged to provide required permissions to users with different roles like Admins, Developers, Testers etc. The principle of least privileges has been followed. As the team expands new users can be easily added to the different groups based on their roles and given the required permissions automatically.
11. An archival strategy for inactive objects greater than 6 months
Data collected as part of Amazon Pinpoint to analyze the application usage will be stored in Amazon S3. After a period of 6 months data will be automatically archived to the Glacier by using the lifecycle management policies.
12. Ability to easily manage and replicate multiple environments based on their blueprint architecture
Infrastructure as Code (IaC) approach is followed to create templates describing all the AWS resource required to set up the complete infrastructure for this application. This is accomplished through AWS CloudFormation Service. Using AWS CloudFormation, the start-up can easily bring up multiple environments on demand or use this methodology to quickly replicate the infrastructure in different regions.
References:
Leave a comment